qnorm(p = 0.01, lower.tail = F)[1] 2.326348Estos ejercicios están orientados al uso de la prueba t de student y la prueba Z para la comparación de una media. Para cada uno de los siguientes problemas, a menos de los que se especifique lo contrario, debe de entregar/realizar lo siguiente:
5.Evaluación de los supuestos + ¿Qué necesito cumplir para poder utilizar la prueba? + ¿Mis datos cumplen con los supuestos? + Si no se cumplen debo seleccionar otra prueba
::: {.Exercise #exr-114}
:::
Los puntos anteriores fueron revisados en la presentación de clase sobre la prueba de hipótesis para la comparación de una media
Tome en cuenta que no en todos los ejercicios se podrán realizar todos los puntos.
Exercise 14.1 Un investigador está interesado en determinar si un nuevo suplemento dietético influye significativamente en el nivel promedio de hierro en la sangre de individuos sanos. Basándose en estudios previos, se conoce que el nivel medio de hierro en la población general es de 60 \(\mu g/dL\) y que la desviación estándar es de 6 \(\mu g/dL\).
Se ha administrado el suplemento dietético a una muestra aleatoria de 50 individuos y, después de un mes de tratamiento, se ha medido el nivel de hierro en la sangre. La media de hierro en esta muestra es de 63 \(\mu g/dL\).
Con estos datos es posible concluir que en los individuos que recibieron el suplemento las concentraciones de hierro son mayores a la de la población. Utilice un nivel de confianza del 99% y asuma que los datos provienen de una distribución normal.
Dado que se conoce la variación poblacional se puede utilizar la prueba Z.
Las hipótesis son:
\(H_0\): Individuos con el suplemento tienen concentraciones de hierro iguales o menores a la de la población
\(H_0 \mu \leq 60\)
\(H_1\): Individuos con el suplmento tienen concentraciones de hierro mayores a la población
\(H_1 \mu > 60\)
Para obtener mi valor crítico:
qnorm(p = 0.01, lower.tail = F)[1] 2.326348El valor de Z de mis datos:
\[Z= \frac{63-60}{ \frac{6}{\sqrt{50}}}=3.54\]
En R lo podemos estimar:
(63-60)/(6/sqrt(50))[1] 3.535534Para la gráfica de decisión se puede utilizar el siguiente código:
y <- (rnorm(10000000, mean=0, sd=1))
den <- density(y)
plot(den, main="Regla de decisión ejemplo práctico 1", xlab="Valores de Z")
value <- qnorm(p = 0.01, lower.tail = F)
polygon(c(den$x[den$x >= value ], value),
c(den$y[den$x >= value ], 0),
col = "slateblue1",
border = 1)
legend(x="topleft", legend = "Zona aceptación zona blanca y
la linea verde estadístico obtenido")
abline(v=(63-60)/(6/sqrt(50)), col="green")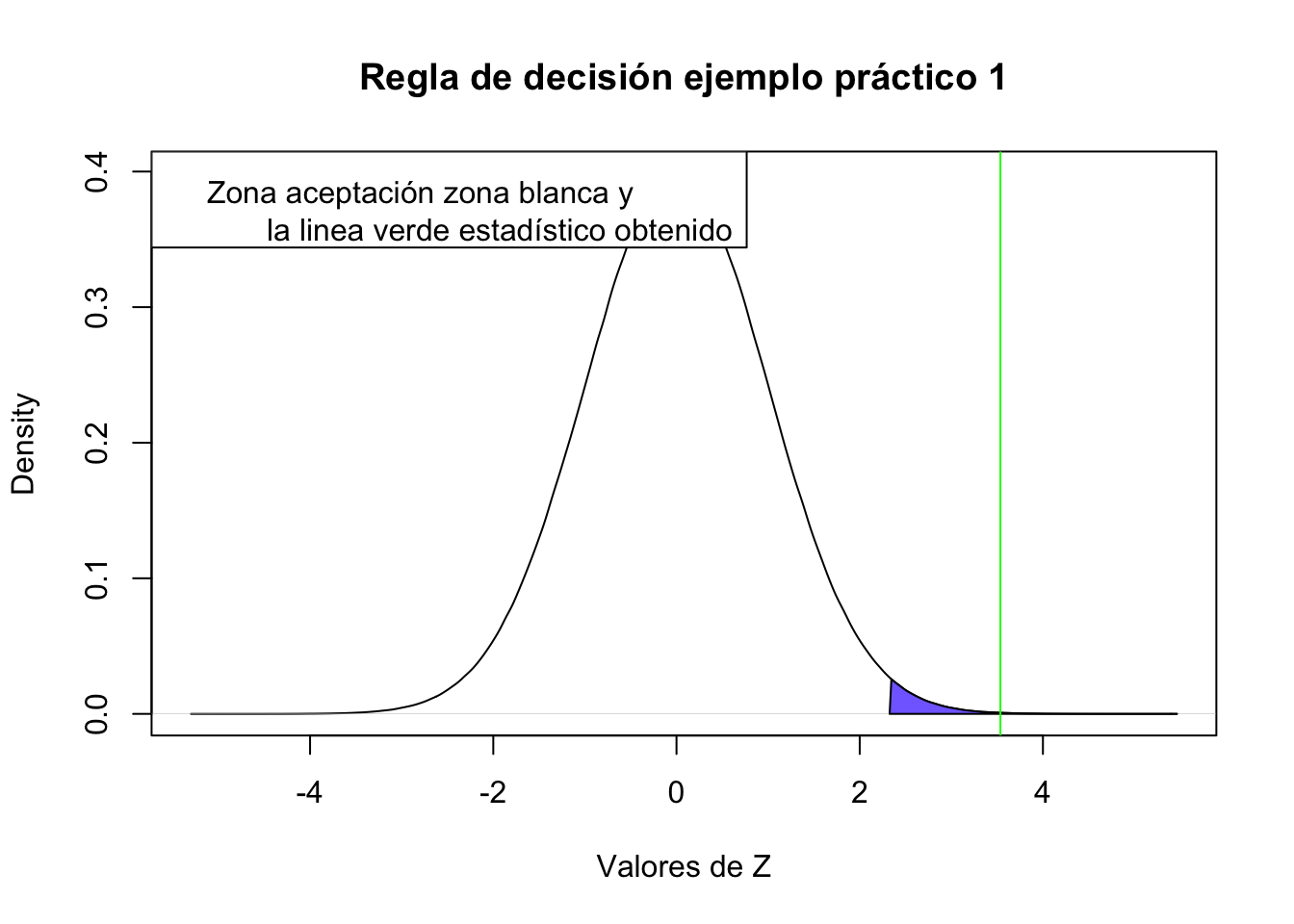
Nuestro valor de Z cae en la zona de rechazo, por lo que tenemos argumentos para rechazar la \(H_0\)
Para estimar el valor de \(p\) se utiliza el siguiente código:
pnorm(q = (63-60)/(6/sqrt(50)), lower.tail = F)[1] 0.000203476Dado que se busca probar si la media de mis datos es mayor a la media poblacional (\(P[X ≤ x]\)) se debe elegir lower.tail=T
Exercise 14.2 En una planta de producción de medicamentos, se requiere que los comprimidos de un fármaco tengan un peso medio de 500 miligramos. Se sabe por especificaciones de calidad que la desviación estándar histórica del peso de los comprimidos es de 50 miligramos. Un control de calidad sospecha que una de las máquinas está descalibrada y está produciendo comprimidos con un peso diferente al estándar.
Usted es parte del equipo de aseguramiento de calidad y se le ha encargado realizar una prueba estadística para determinar si la máquina en cuestión está funcionando correctamente. Para ello, se toma una muestra aleatoria de 40 comprimidos producidos por la máquina y se encuentra que el peso medio de esta muestra es de 510 miligramos
Determine si la máquina necesita recalibración. Utilice \(\alpha=0.05\) y asuma que los datos provienen de una distribución normal y que la desviación estándar histórica es la poblacional.
Dado que se conoce la variación poblacional se puede utilizar la prueba Z.
Las hipótesis son:
\(H_0\): El equipo se encuentra calibrado con respecto al peso medio del fármaco de 500 mg. No necesita recalibración
\(H_0: \mu = 500 mg\)
\(H_1\): El equipo se encuentra descalibrado con respecto al peso medio del fármaco de 500 mg. Necesita recalibración
\(H_0: \mu \neq 500mg\)
Para obtener mi valor crítico:
qnorm(p = 0.025, lower.tail = F)[1] 1.959964qnorm(p = 0.025, lower.tail = T)[1] -1.959964El valor de Z de mis datos:
\[Z= \frac{510-500}{ \frac{50}{\sqrt{40}}}=1.26\]
En R lo podemos estimar:
(510-500)/(50/sqrt(40))[1] 1.264911Para la gráfica de decisión se puede utilizar el siguiente código:
y <- (rnorm(10000000, mean=0, sd=1))
den <- density(y)
plot(den, main="Regla de decisión ejemplo práctico 1", xlab="Valores de Z")
value <- qnorm(p = 0.025, lower.tail = F)
polygon(c(den$x[den$x >= value ], value),
c(den$y[den$x >= value ], 0),
col = "slateblue1",
border = 1)
value <- qnorm(p = 0.025, lower.tail = T)
polygon(c(den$x[den$x <= value ], value),
c(den$y[den$x <= value ], 0),
col = "slateblue1",
border = 1)
legend(x="topleft", legend = "Zona aceptación zona blanca y
la linea verde estadístico obtenido")
abline(v=(510-500)/(50/sqrt(40)), col="green")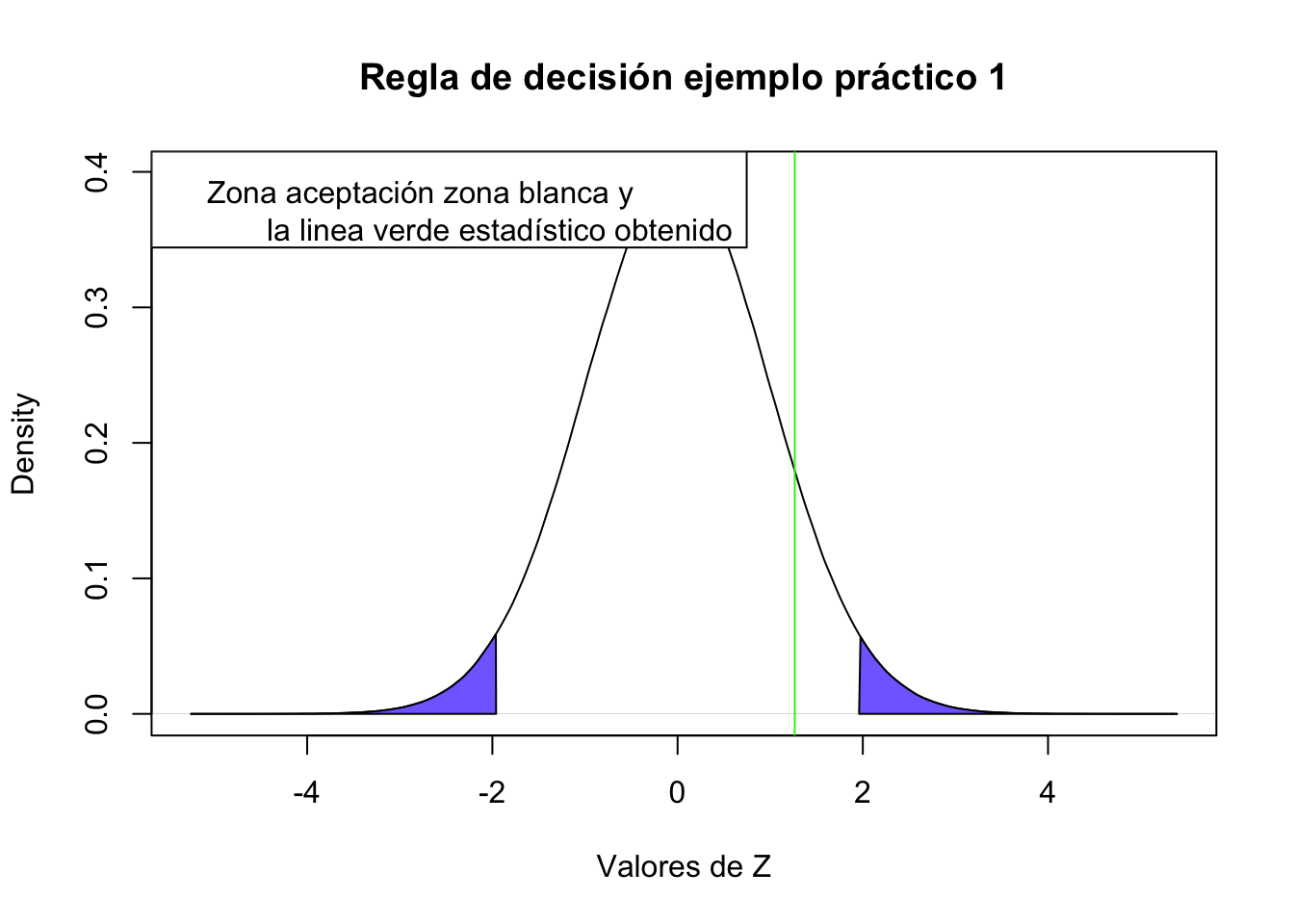
Nuestro valor de Z cae en la zona de aceptación, por lo que NO tenemos argumentos para rechazar la \(H_0\)
Para estimar el valor de \(p\) se utiliza el siguiente código:
pnorm(q = (510-500)/(50/sqrt(40)), lower.tail = F)*2[1] 0.2059032Exercise 14.3 La base de datos Pima.tr2 contiene datos sobre el grupo de indios Pima y varios predictores de diabetes. Uno de los atributos medidos en esta base de datos es la glucosa en plasma a 2 horas en una prueba de tolerancia oral a la glucosa.
Se quiere investigar si el nivel medio de glucosa en plasma a 2 horas en el grupo de los indios Pima es significativamente diferente del valor de glucosa considerado como punto de corte para diagnóstico de diabetes, que es de 140 mg/dL. La desviación estándar de la glucosa en la población es conocida y es de 30 mg/dL.
Determine si hay una diferencia significativa entre la media muestral y el valor de corte de 140 mg/dl. Utilice \(\alpha=0.05\) y asuma que los datos provienen de una distribución normal.
Exercise 14.4 La base de datos birthwt del paquete MASS incluye datos de un estudio sobre factores de riesgo para el bajo peso al nacer. Entre las variables registradas está el peso del recién nacido en gramos (bwt).
Se desea examinar si el peso promedio al nacer en la muestra proporcionada es significativamente diferente del promedio nacional que se considera normal, el cual es de 3400 gramos. Se conoce que la desviación estándar del peso al nacer a nivel nacional es de 500 gramos.
Realice una prueba Z para determinar si existe una diferencia significativa entre la media muestral y el promedio nacional de 3400 gramos.
Exercise 14.5 Los investigadores Bertino et al. condujeron un estudio para examinar los datos recolectados correspondientes a la farmacocinética de la gentamicina en tres poblaciones mayores de 18 años: pacientes con leucemia aguda, pacientes con otros padecimientos malignos no leucemicos y pacientes sin enfermedad maligna oculta o fisiopatologías distintas de la insuficiencia renal que se sabe alteran la farmacocinética de la gentamicina. Entre las estadísticas reportadas por los investigadores estaba el valor 59.1 como media inicial calculada de la depuración de creatina, con una desviación estándar poblacional de 25.6. Tomaron una muestra de 211 pacientes con enfermedad maligna distinta de la leucemia. Se pretende saber si es posible concluir que la media para la población de individuos que presentan enfermedad maligna distinta de la leucemia es menor que 60. Utilice un valor de alfa de 0.10. Asuma que los datos siguen una distribución normal. Ejercicio tomado de BIOESTADISTICA (2016) de Wayne W. Daniel (Autor)
Se conoce la varianza poblacional por lo que se puede empelar Z
Se pretende saber si es posible concluir que la media para la población de individuos que presentan enfermedad maligna distinta de la leucemia es menor que 60
Necesitamos probar que la media de una población con varianza conocida es menor que 60, por ello empleamos el estadísticos \(z\)
Rutilizamos la función qnormqnorm(0.10)#Necesitamos solo el valor del lado izquierdo[1] -1.281552plot(density(rnorm(1000000, mean=0, sd=1)), main = "Regla de decisión",
xlab = "Valor de Z", ylab="")
abline(v=(qnorm(0.10)), col="red", lw=4)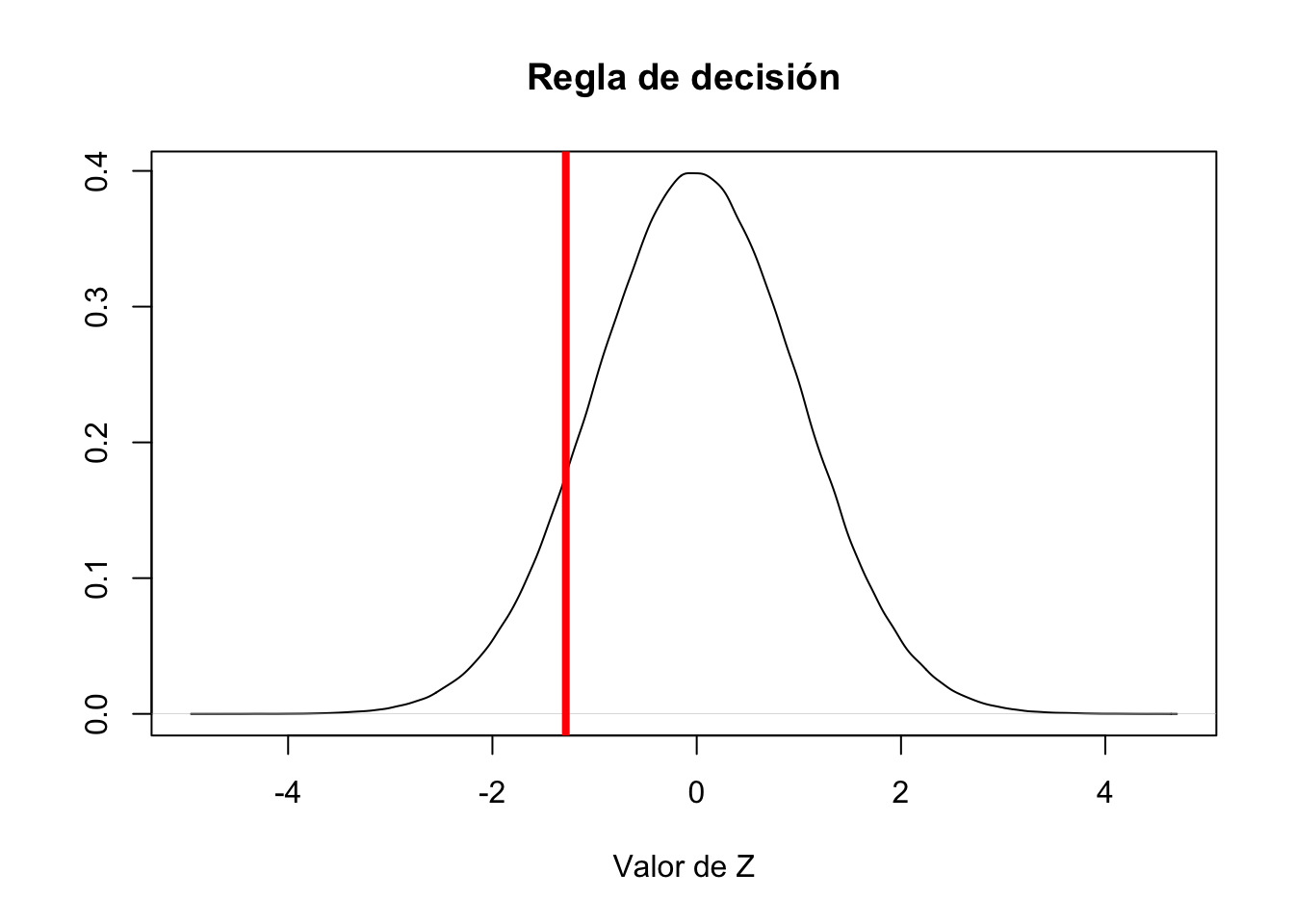
\(z= \frac{ \bar{x}- \mu_0}{\sigma/ \sqrt{n}}\)
\(z= \frac{ 59.1-60}{25.6/ sqrt(211)}\)
R lo podemos hacer utilizando el siguiente código:(59.1-60)/(25.6/sqrt(211))[1] -0.510674Con base en la regla de decisión, no exisite evidencia para rechazar la hipótesis nula porque -0.510674 es mayor que -1.2815516
Gráficamente lo podemos ver:
plot(density(rnorm(1000000, mean=0, sd=1)), main = "Regla de decisión",
xlab = "Valor de Z", ylab="")
abline(v=(qnorm(0.10)), col="red", lw=4)
abline(v=((59.1-60)/(25.6/sqrt(211))), col="green", lw=4)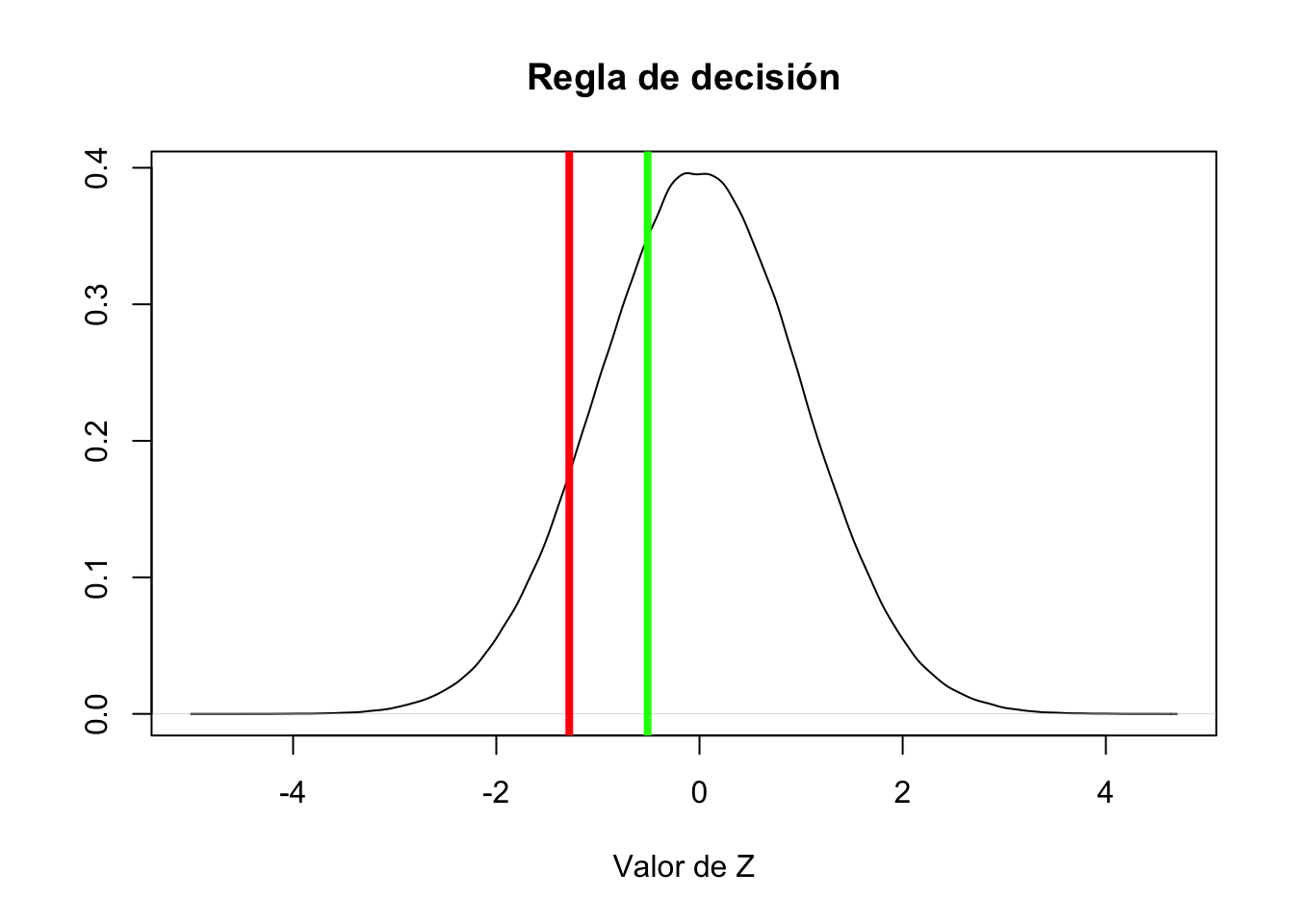
Con un 95% de confianza podemos decir que la media poblacional no es distinta de 60
En r lo podemos calcular con la función pnorm
pnorm((59.1-60)/(25.6/sqrt(211)))[1] 0.3047897Dado que nuestra hipótesis es unilateral NO debemos de sumar probabilidades
El valor p es mayor que \(\alpha\) no es posible rechazar la hipótesis nula.
Exercise 14.6 Supongamos que se está investigando la eficacia de un nuevo programa de ejercicios diseñado para mejorar la capacidad cardiovascular. Según estudios previos, se sabe que el índice promedio de capacidad cardiovascular en la población adulta es de 50 mL/kg/min (mililitros de oxígeno por kilogramo de peso corporal por minuto)
Un grupo de 20 voluntarios participa en el nuevo programa de ejercicios durante 8 semanas. Al final del programa, se mide su capacidad cardiovascular. Los resultados son los siguientes (en mL/kg/min):
52,54,55,53,54,56,57,55,58,59,51,52,53,54,55,56,57,58,54,53
Determine si la media de capacidad cardiovascular del grupo después del programa es significativamente diferente del promedio conocido de 50 mL/kg/min. Asuma que los datos siguen una distribución normal. Utilice un nivel de confianza del 98%
Exercise 14.7 Se ha desarrollado un nuevo método de enseñanza de matemáticas destinado a mejorar las calificaciones de los estudiantes de secundaria en sus exámenes finales. Para evaluar la efectividad de este método, se realizó un estudio con un grupo de estudiantes que lo siguieron durante un semestre. Históricamente, la calificación media en el examen final de matemáticas para la población de estudiantes de secundaria ha sido de 75 puntos, con una desviación estándar poblacional desconocida.
Un grupo de 15 estudiantes participa en el estudio y, al final del semestre, obtienen las siguientes calificaciones en el examen final de matemáticas:
78,74,77,80,82,75,73,76,78,81,77,74,79,80,76
determinar si la media de las calificaciones de los estudiantes que siguieron el nuevo método de enseñanza es significativamente diferente de la media histórica de 75 puntos.
Establecer un nivel de significancia del 5% (\(\alpha\) = 0.05). Asuma que los datos siguen una distribución normal.
Exercise 14.8 Algunos investigadores suponen que la media de la temperatura normal del cuerpo es menor a 98.6ºF. ¿Existe evidencia estadística que demuestre que los investigadores tienen la razón? Para resolver este problema utilice la base de datos “BodyTemperature.txt” que descargar de aquí. Utilice \(\alpha=0.05\)
Utilizando la base de datos “BodyTemperature.txt” evalúe:
Exercise 14.9 Una de las variables registradas en Pima.tr2 es la presión sanguínea diastólica (bp). Se desea investigar si la presión sanguínea diastólica media de las mujeres en el estudio difiere del valor estándar considerado normal de 80 mmHg.
Determine si la presión sanguínea diastólica media en la muestra de Pima.tr2 es significativamente diferente de 80 mmHg. Utilice \(\alpha=0.05\) y asume una distribución normal.
Exercise 14.10 Repita el ejercicio anterior pero esta vez pruebe si la bp es significativamente diferente de 72 mmHg. Utilice \(\alpha=0.05\) y asume una distribución normal.
¿Qué pasa si se cambia a un nivel de confianza del 90%?
Exercise 14.11 Este ejercicio se centrará en las pacientes diagnosticadas con diabetes y explorará si su nivel medio de glucosa difiere del valor de referencia de 126 mg/dL, que es el umbral para el diagnóstico de diabetes según la Organización Mundial de la Salud (OMS). Realice lo siguiente:
Exercise 14.12